Services
Overview
It is a common practice to have several VMs or containers to do a specific job, like serving web content or processing specific data. For big infrastructures, instantiating and managing all of these virtual instances can become complex. Services allows users and administrators to define, execute and manage multi-tiered applications. These are composed of interconnected Virtual Machines or containers with deployment dependencies between them. Each group of Virtual Machines is deployed and managed as a single entity, and is completely integrated with the advanced HyperCX user and group management. Services is available since HyperCX 10.5.3. Virtalus will provide some preconfigured services like Kubernetes clusters managed as services.
What Is a Service?
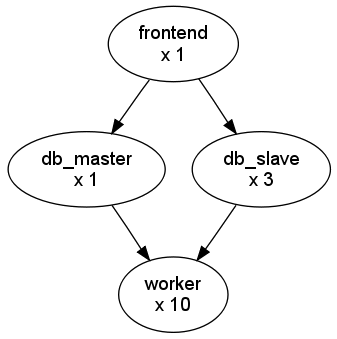
The following diagram represents a multi-tier application. Each node represents a Role, and its cardinality (the number of VMs that will be deployed). The arrows indicate the deployment dependencies: each Role’s VMs are deployed only when all its parent’s VMs are running.
Managing Service Templates
To deploy a service, a service template must be created first. These Templates can be then instantiated several times, and also shared with other users.
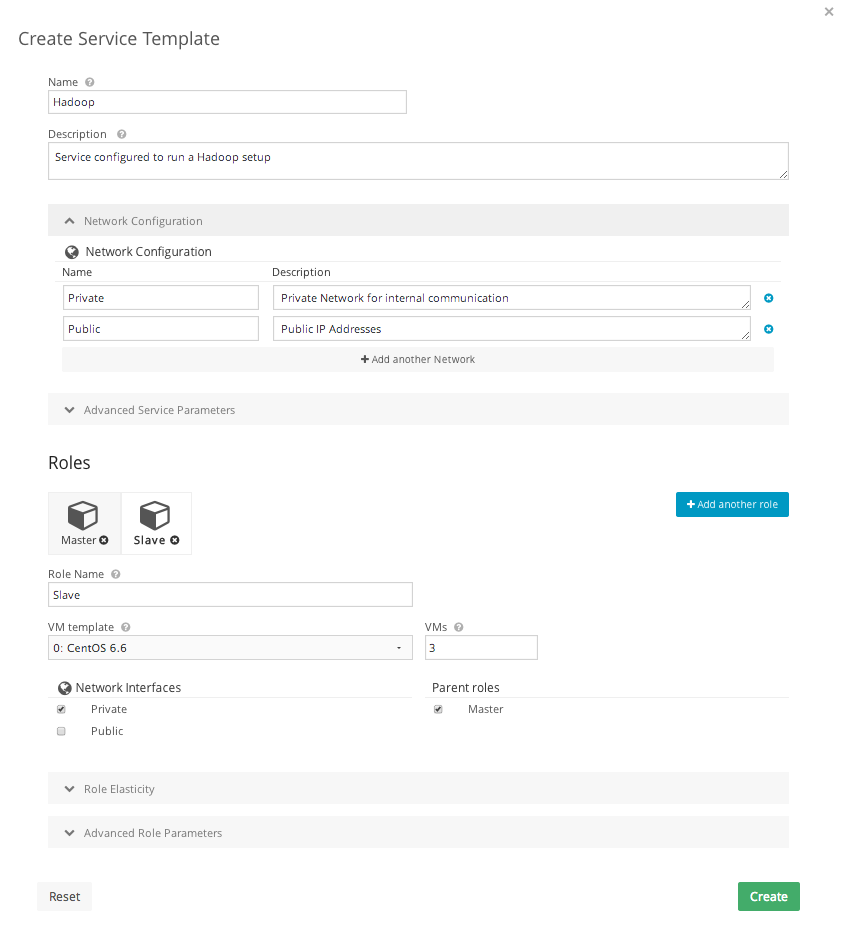
Create Service Templates
You can create Service Templates from the web interface:
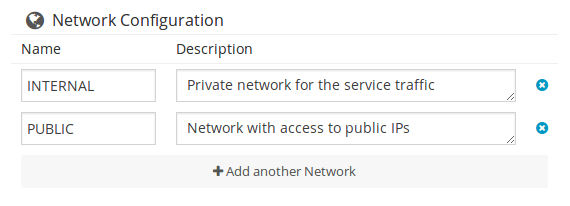
Configure Dynamic Networks
Each Service Role has a Virtual Machine Template assigned. The VM Template will define the capacity, disks, and network interfaces. But instead of using the Virtual Networks set in the VM Template, the Service Template can define a set of dynamic networks.
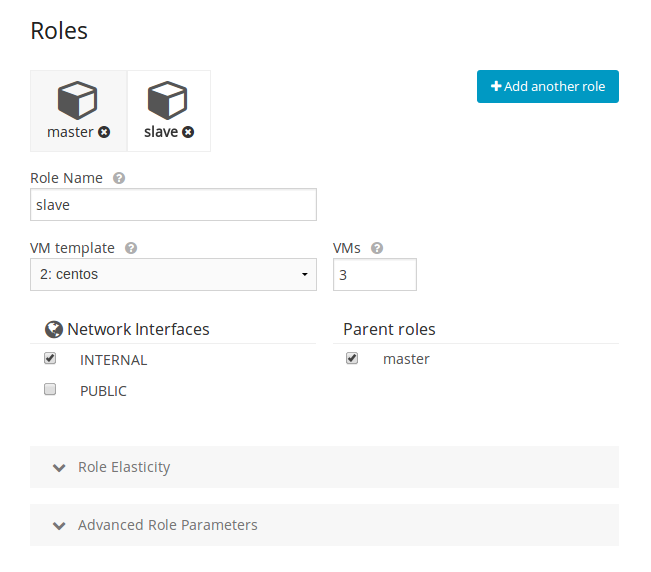
Each Role can be attached to the dynamic networks individually.
When a Service Template defines dynamic networks, the instantiate dialog will ask the user to select the networks to use for the new Service.
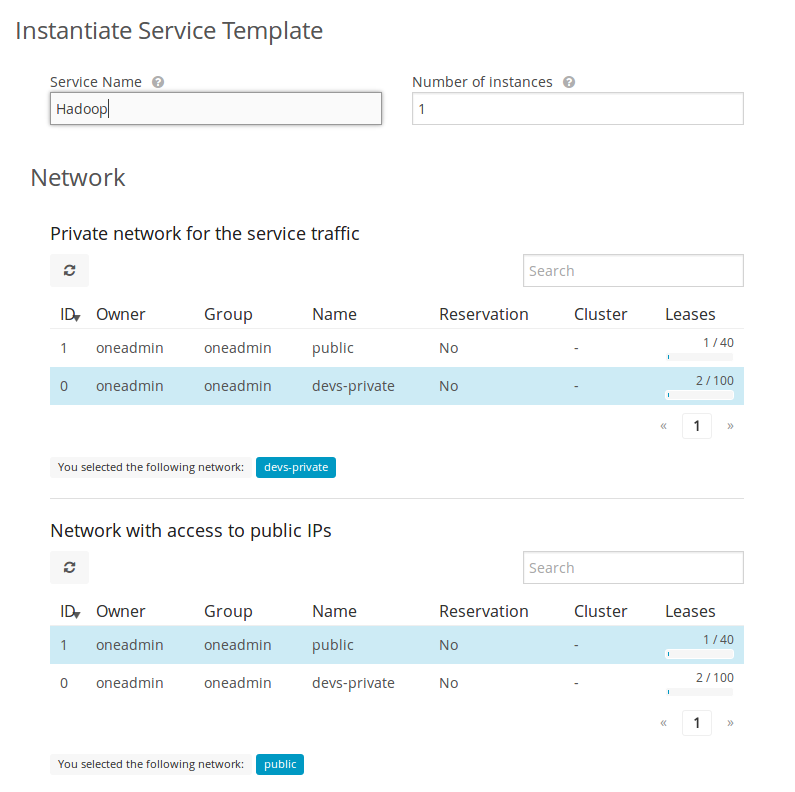
This allows you to create more generic Service Templates. For example, the same Service Template can be used by users of different groups that may have access to different Virtual Networks. This is useful for private clouds and other multi-tenant environments.
Advanced Service Parameters
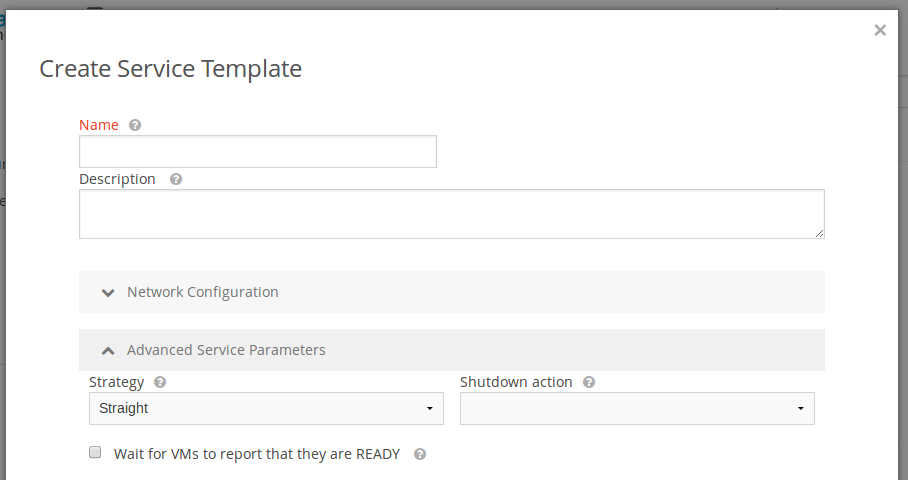
When multiple roles are defined, it is important in some cases to define a deployment strategy. If no strategy is selected, roles will be instantiated regardless of their hierarchy (in no specific order). If straight strategy is selected, each role will be instantiated in order: parents role will be deployed before their children.
VM shutdown action defines how to destroy the VMs that belong to a service once the service is destroyed. By default (if nothing is selected), terminate-hard will be used.
Depending on the deployment strategy, HyperCX will wait until all the VMs in a specific Role are in running state before deploying VMs that belong to a child Role. How HyperCX determines the running state of the VMs can be specified with the checkbox Wait for VMs to report that the are READY available in the Service creation dialog in the web interface. If this option is not selected, as soon as the VM is in RUNNING state (marked by the hypervisor), VMs belonging to the next role will start to be deployed. This means that as soon as the OS starts to boot up other roles will start launching VMs. In some cases, a child role might require that the services installed on the VMs of the parent role are listening for requests, and this might take some time depending on how heavy these services are (or the VMs can fail to properly boot up). For these cases, this option should be checked. This will make each VM to report to HyperCX as soon as the OS finished loading and the services are up. This means that the service will take longer but it will guarantee that VMs from a child role are not launched until the VMs from the parent role are fully initialized.
Note
For the previously described feature to work, the VM templates assigned to each role will require the options Add OneGate token and Report Ready to OneGate. These options can be found on the Context section of the VM template.
Roles
Roles are the different layers of a service. For example, on a multi-tier architecture, each tier can be seen as a role. Each role will require a name and a template. One or more VMs can be configured to be launched by the role, this is the amount of times the selected template will be initially instantiated. This is referred to as cardinality. This cardinality can be adjusted after the service has been instantiated.
Managing Services
A Service Template can be instantiated as a Service. Each newly created Service will be deployed by HyperCX following its deployment strategy.
Each Service Role creates Virtual Machines in HyperCX from VM Templates, that must exist beforehand.
Create and List Existing Services
New Services are created from Service Templates.
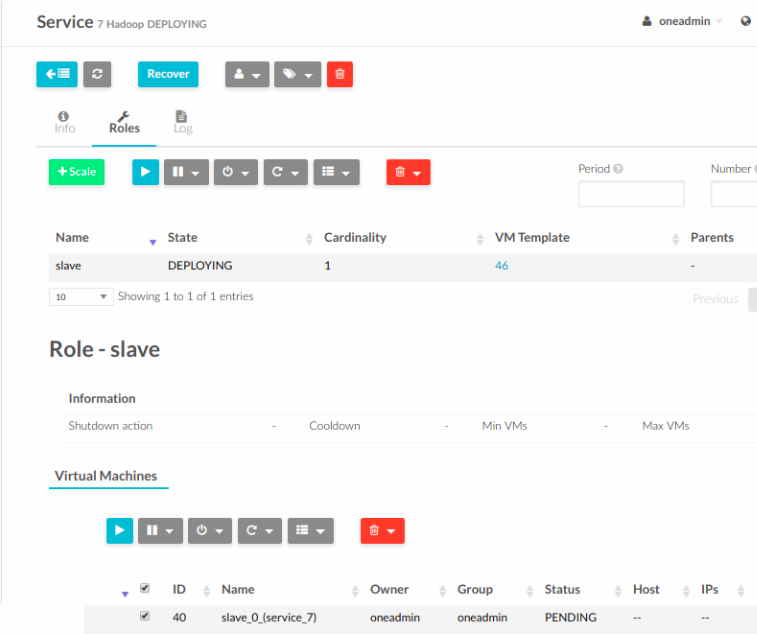
The Service will eventually change to DEPLOYING.
Life-cycle
The deployment attribute defines the deployment strategy that the life cycle manager will use. These two values can be used:
- none: All Roles are deployed at the same time.
- straight: Each Role is deployed when all its parent Roles are
RUNNING.
Regardless of the strategy used, the Service will be RUNNING when all of the Roles are also RUNNING. Likewise, a Role will enter this state only when all the VMs are running.
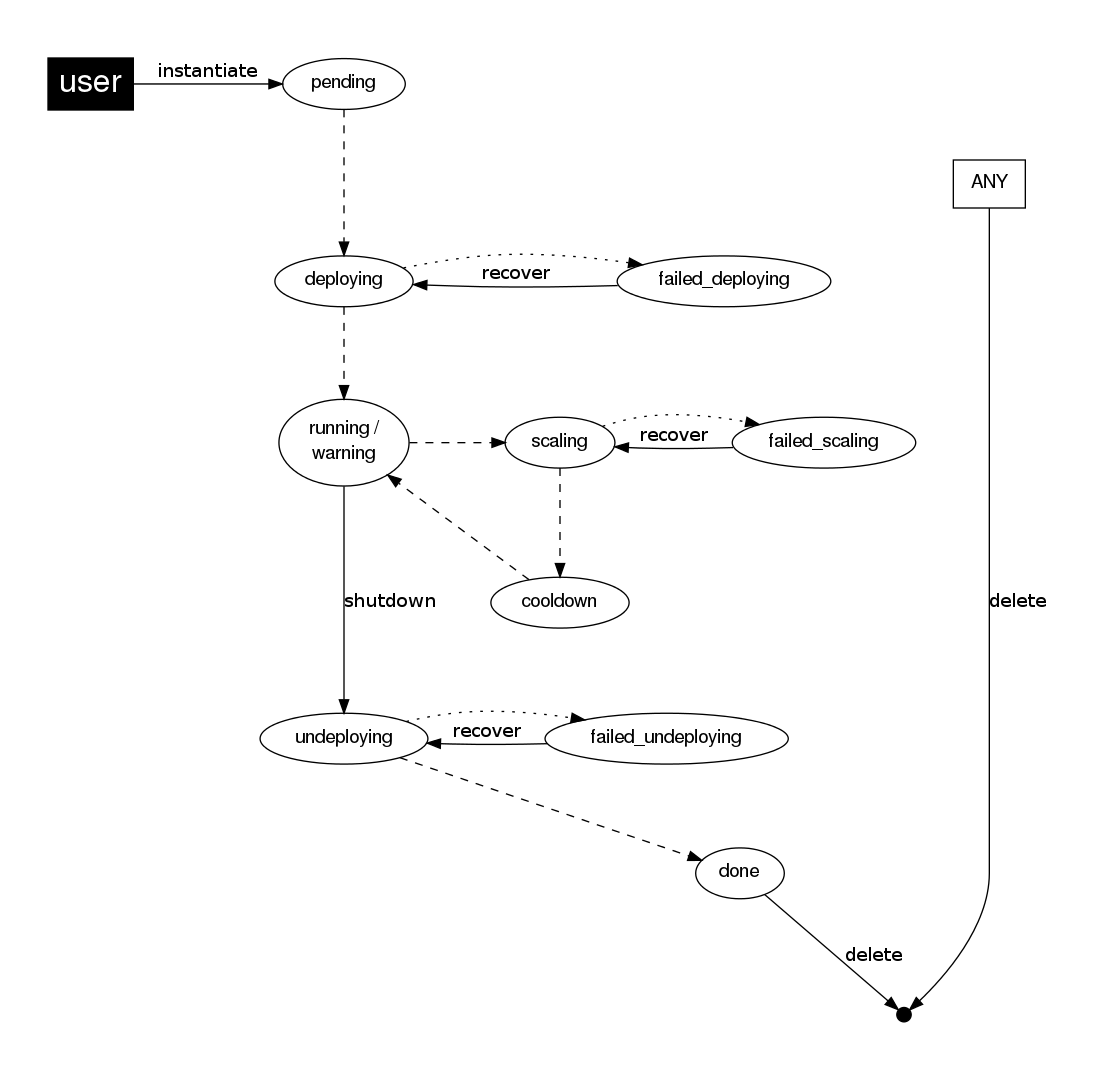
This table describes the Service states:
| Service State | Meaning |
|---|---|
PENDING |
The Service starts in this state, and will stay in it until the LCM decides to deploy it. |
DEPLOYING |
Some Roles are being deployed. |
RUNNING |
All Roles are deployed successfully. |
WARNING |
A VM was found in a failure state. |
SCALING |
A Role is scaling up or down. |
COOLDOWN |
A Role is in the cooldown period after a scaling operation. |
UNDEPLOYING |
Some Roles are being undeployed. |
DONE |
The Service will stay in this state after a successful undeployment. It can be deleted. |
FAILED_DEPLOYING |
An error occurred while deploying the Service. |
FAILED_UNDEPLOYING |
An error occurred while undeploying the Service. |
FAILED_SCALING |
An error occurred while scaling the Service. |
Each Role has an individual state, described in the following table:
| Role State | Meaning |
|---|---|
PENDING |
The Role is waiting to be deployed. |
DEPLOYING |
The VMs are being created, and will be monitored until all of them are running. |
RUNNING |
All the VMs are running. |
WARNING |
A VM was found in a failure state. |
SCALING |
The Role is waiting for VMs to be deployed or to be shutdown. |
COOLDOWN |
The Role is in the cooldown period after a scaling operation. |
UNDEPLOYING |
The VMs are being shutdown. The Role will stay in this state until all VMs are done. |
DONE |
All the VMs are done. |
FAILED_DEPLOYING |
An error occurred while deploying the VMs. |
FAILED_UNDEPLOYING |
An error occurred while undeploying the VMs. |
FAILED_SCALING |
An error occurred while scaling the Role. |
Services Auto-scaling
A Service Role’s cardinality can be adjusted manually, based on metrics, or based on a schedule.
Overview
When a scaling action starts, the Role and Service enter the SCALING state. In this state, the Role will instantiate or terminate a number of VMs to reach its new cardinality.
After the scaling, the Role and Service are in the COOLDOWN state for the configured duration. During a scale operation and the cooldown period, other scaling actions for the same or for other Roles are delayed until the Service is RUNNING again.
Set the Cardinality of a Role Automatically
Auto-scaling Types
Both elasticity_policies and scheduled_policies elements define an automatic adjustment of the Role cardinality. Three different adjustment types are supported:
- CHANGE: Add/subtract the given number of VMs.
- CARDINALITY: Set the cardinality to the given number.
- PERCENTAGE_CHANGE: Add/subtract the given percentage to the current cardinality.
Interaction with Individual VM Management
All the VMs created by a Service can be managed as regular VMs. When VMs are monitored in an unexpected state, this is what HyperCX interprets:
- VMs in a recoverable state (‘suspend’, ‘poweroff’, etc.) are considered healthy machines. The user will eventually decide to resume these VMs, so HyperCX will keep monitoring them. For the elasticity module, these VMs are just like ‘running’ VMs.
- VMs in the final ‘done’ state are cleaned from the Role. They do not appear in the nodes information table, and the cardinality is updated to reflect the new number of VMs. This can be seen as an manual scale-down action.
- VMs in ‘unknown’ or ‘failed’ are in an anomalous state, and the user must be notified. The Role and Service are set to the ‘WARNING’ state.